Apache Spark - Tutorial 1

I am a data engineer who is responsible for designing, building, maintaining, and testing the infrastructure and systems that are used to store, process, and analyze data. I work closely with data scientists and analysts to ensure that the data pipelines and systems are able to support the data needs of an organization.
I have a strong background in computer science and software engineering, and skilled in programming languages such as Python, Java, and SQL also familiar with database systems and big data technologies like Hadoop, Spark, and NoSQL databases.
Some of my key responsibilities as a data engineer:
Designing and building data pipelines to extract, transform, and load data from various sources Setting up and maintaining data storage and processing systems, including data warehouses and data lakes Collaborating with data scientists and analysts to understand their data needs and ensure that the data infrastructure can support their requirements Performing data quality checks and troubleshooting any issues that arise Implementing security and privacy measures to protect sensitive data
First We need to understand why Spark?
There are some Drawbacks in Hadoop MapReduce processing and then Spark came into the game.
The below points can be the most listed drawbacks of MapReduce:
It's only made for Batch Processing
CDC - Change Data Capture is not possible in MapReduce
Slow processing - because of 'In memory' computation not implemented
- 'In Memory' computation means utilizing the memory as much as possible while processing.
Not fault tolerant in terms of computation - If any failure occurs it will be starting from stage 1 and re-computation from the failure stage is not implemented.
No mechanism implemented for caching persists.
To overcome the above points, we use Spark as our processing engine.
Apache Spark

Apache Spark is an open-sourced distributed computation framework that provides a wide range of functionality for data processing, including streaming, batch data processing, machine learning task and graph kind of data processing.
It was designed to be fast and flexible to process a large amount of data effectively.
Spark is built on top of Scala programming language and uses a distributed data processing model called Resilient Distributed Data (RDD).
It does not have any inbuilt file system or storage mechanism.
Features of Spark
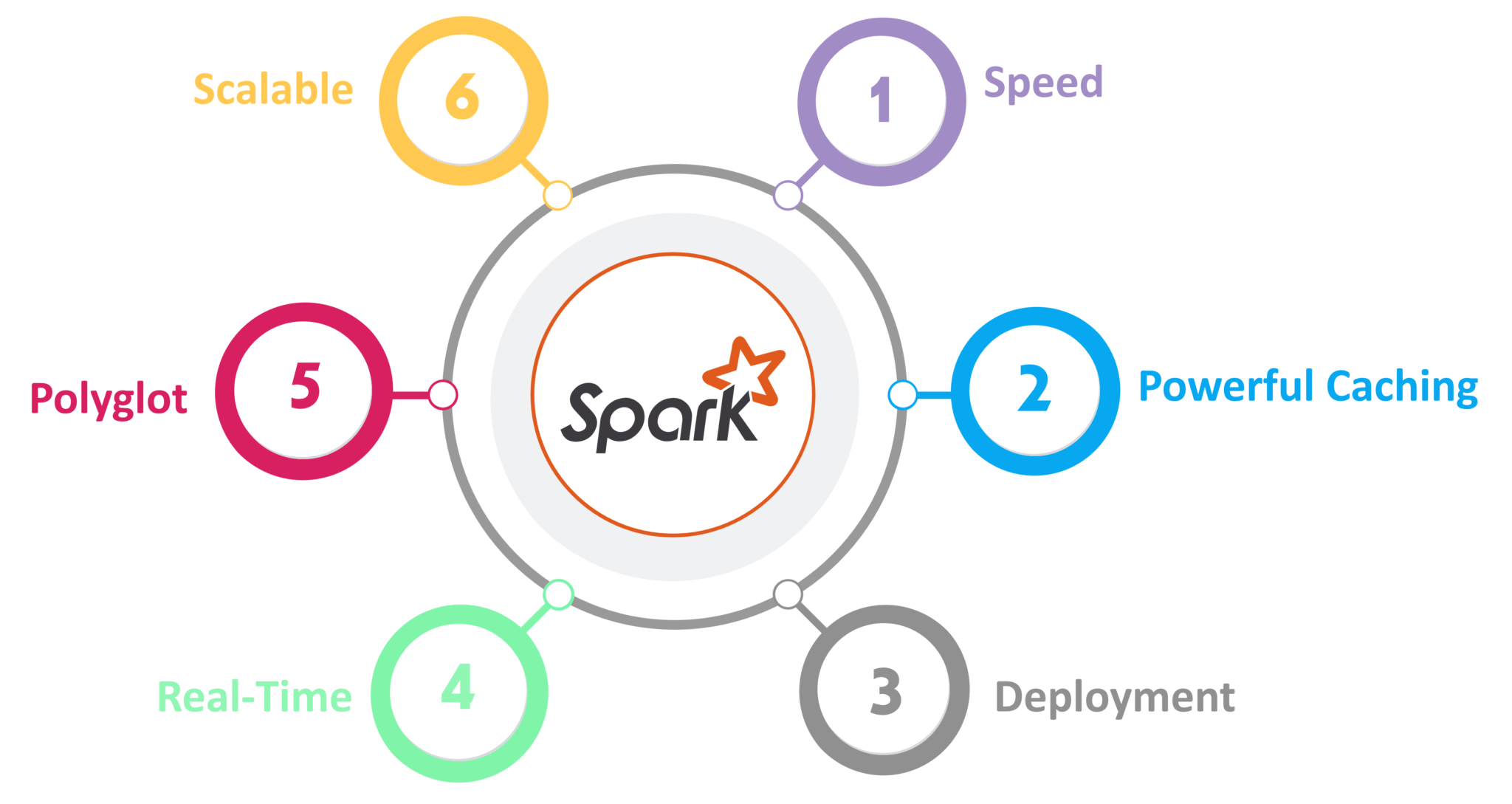
Speed - It is 100 times faster than Hadoop - This is officially proven.
Powerful Caching - Capability to persist the data in memory while processing.
Multiple Deploy method - We can deploy with the below Resource manager for Spark
YARN
Mesos
Kubernetes
Spark own cluster manager.
Good fit for Batch and Real-time processing
Polyglot - Spark provides high-level API for different languages - Python, Scala, Java and R.
Spark Architecture
Apache Spark has a Master-Slave architecture in which a central coordinator (driver program) manages a group of worker nodes (executors) that executes the tasks.
When a spark application starts immediately driver program has been initiated on the machine where the SparkContext or SparkSession was created. After that Spark Context will connect with YARN for resource allocation. YARN will create an Application master on any one of the nodes and this will ask to create several executors based on our requirements. Once resource allocation is completed, the Driver program connects with Executors to execute the tasks parallel and share the data through shared memory.
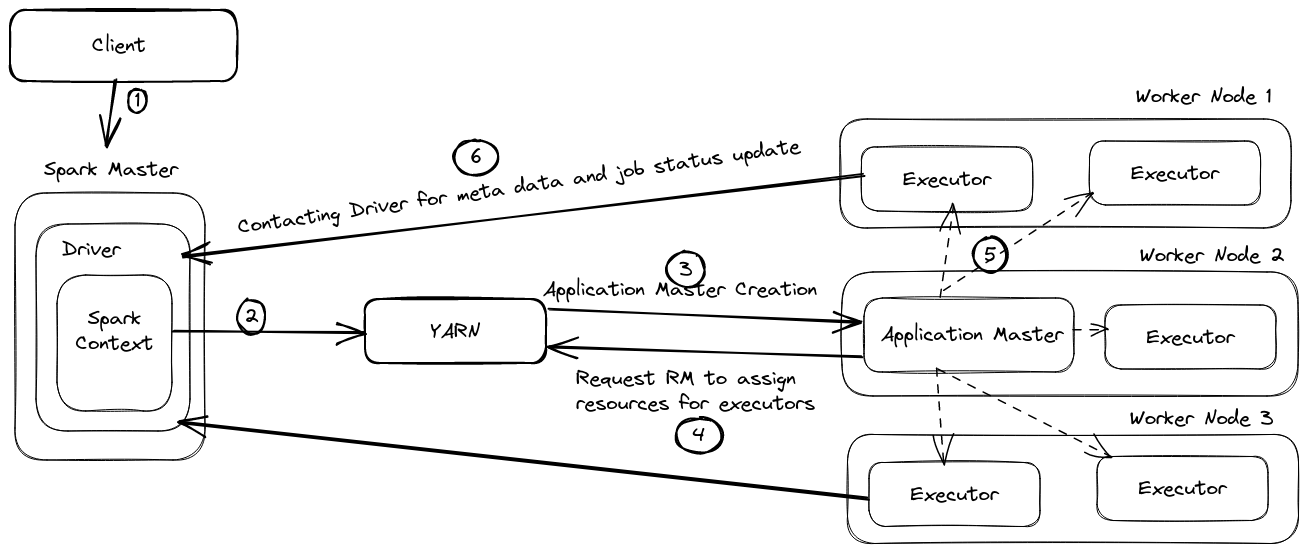
Client
Can be any machine from where we are sending our spark job for execution
Like Remote servers, web interfaces
Spark shell - Used as an interactive shell - Available only in Python and Scala.
Spark submit - when you have a complete spark application.
Spark Master - Driver Program and Spark Context
Driver Program
It acts as the central coordinator which will create Spark context and it is responsible for several key tasks,
Creating and managing SparkContext or SparkSession
Scheduling the tasks.
Executing the tasks on executors
Sending the results back to the client
Spark Context or Spark Session
It is the entry point to the spark cluster for your spark application.
Spark Session is used to create RDD's, accumulators, and broadcast variables as well as to execute the transformation and actions.
Before Spark 2, Spark Context was used separately. After Spark 2, the Spark session will do all things.
Also, it includes some additional features which were maintained in different libraries earlier, such as reading and writing data from various sources and executing SQL queries.
import org.apache.spark.sql.SparkSession
spark = SparkSession\
.builder()\
.appName("My Spark Application")\
.config("spark.some.config.option", "some-value")\
.getOrCreate()
Resource Manager
It will create one virtual container and start the Application master service in it.
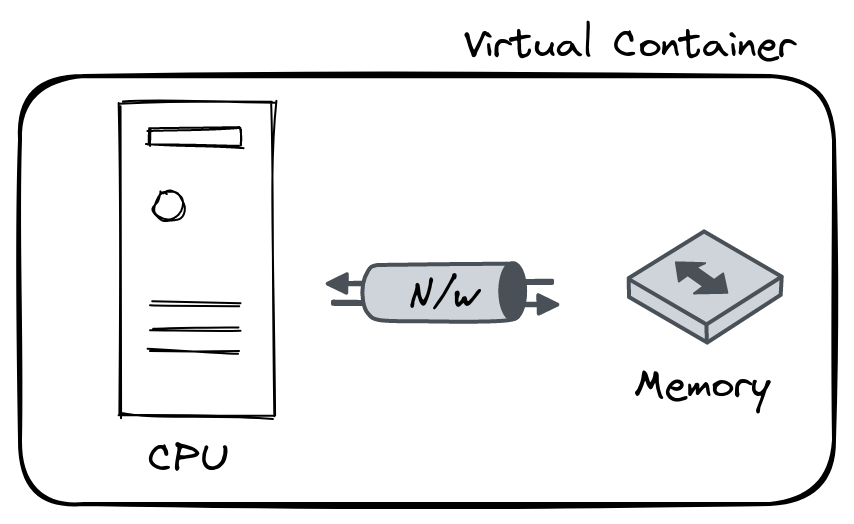
The application Master will request to resource manager for complete resource allocation to start the required executors.
Resource Manager will create the required number of executors for processing
Executors
Application masters and executors are virtual entity will have CPU, Memory and Network Bandwidth.
An executor does the actual computation on the partition Data.
Executors will start interacting with the Driver program for metadata and on-time job status updates.
Let us see this architecture with a small example to understand it deeply.
Task
A small unit of execution is known as a task.
Each task will process one spark data partition.
One task will be executed on one CPU core.
One executor can run multiple tasks as per the available or assigned CPU cores.
Spark with YARN
let us assume we have Three worker nodes each have 256 GB Memory, 32 CPU cores
We need to execute two Spark jobs and one job needs 3 executors, each executor should have 5 CPU cores with 32 GB of memory. And another one needs 1 executor - 3 CPU cores with 32 GB memory.
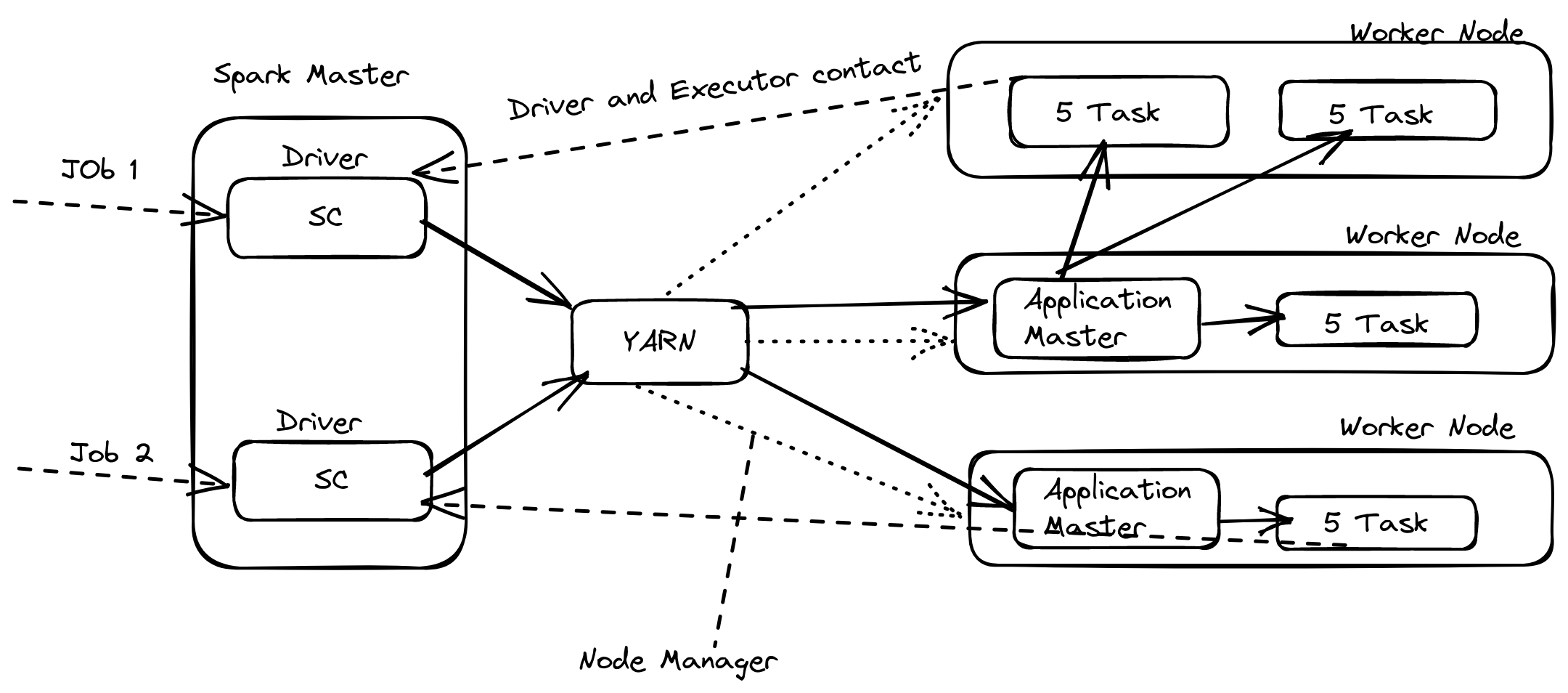
Based on our requirements spark can assign the resources and execute the jobs as shown in the above flow.
Now understand the CPU and task relationship:-
In Map reduce we need one CPU core per map task. Same as that we need one CPU core per one spark task.
Task and CPU core are more important for executing jobs in parallel.
