Spark Submit
From Now on we are going to use spark Submit frequently So that we are going to learn the Syntax for Spark Submit first,
Once the Spark application build is completed, we use to execute that application via the spark-submit command.
spark-submit\
--master <master-url>\
--deploy_mode <cluster or client>\
--conf <key:value>\
--driver-memory ng\
--executor-memory ng\
--executor-cores n\
--num-executors n\
--jars <comma seperated jar file names>\
examplePySpark.py <arg1> <arg2>
Master
Here we need to add our Spark master node URL
Deploy Mode:
There are two types of deployment modes available,
Client Mode: When we add the client as deploy mode, the Driver Program will be created in Our Client Machine. This is useful when you are working on the development of a Spark application and it should not be followed when your application goes into Production. As we know our executors always contact with Driver Program on executions so the client configuration is not advisable for Production.
Cluster Mode: In Cluster mode, your Driver Program will be created on any one of the Worker nodes, So that the communication between the executors will be faster. This mode is used in most of the Production.
The Default Mode is Client
Conf
Arbitrary Spark configuration property in key=value format. For values that contain spaces wrap “key=value” in quotes.
Driver Memory
Here you can add how much driver memory need for your application.
Executor Memory
This is used to configure the executory Memory, Example 4g,
Executor Cores
How many CPU cores do you need for your application
Number of Executors
Can be used to configure the required number of executors
Jars
Path to a bundled jar including your application and all dependencies
Now dive into the most important core concept of Spark.
RDD - Resilient Distributed DataSet
RDDs are the main logical data units in Spark
They have distributed collections of objects which are stored in memory or on disks of different nodes of a cluster.
Features of RDD
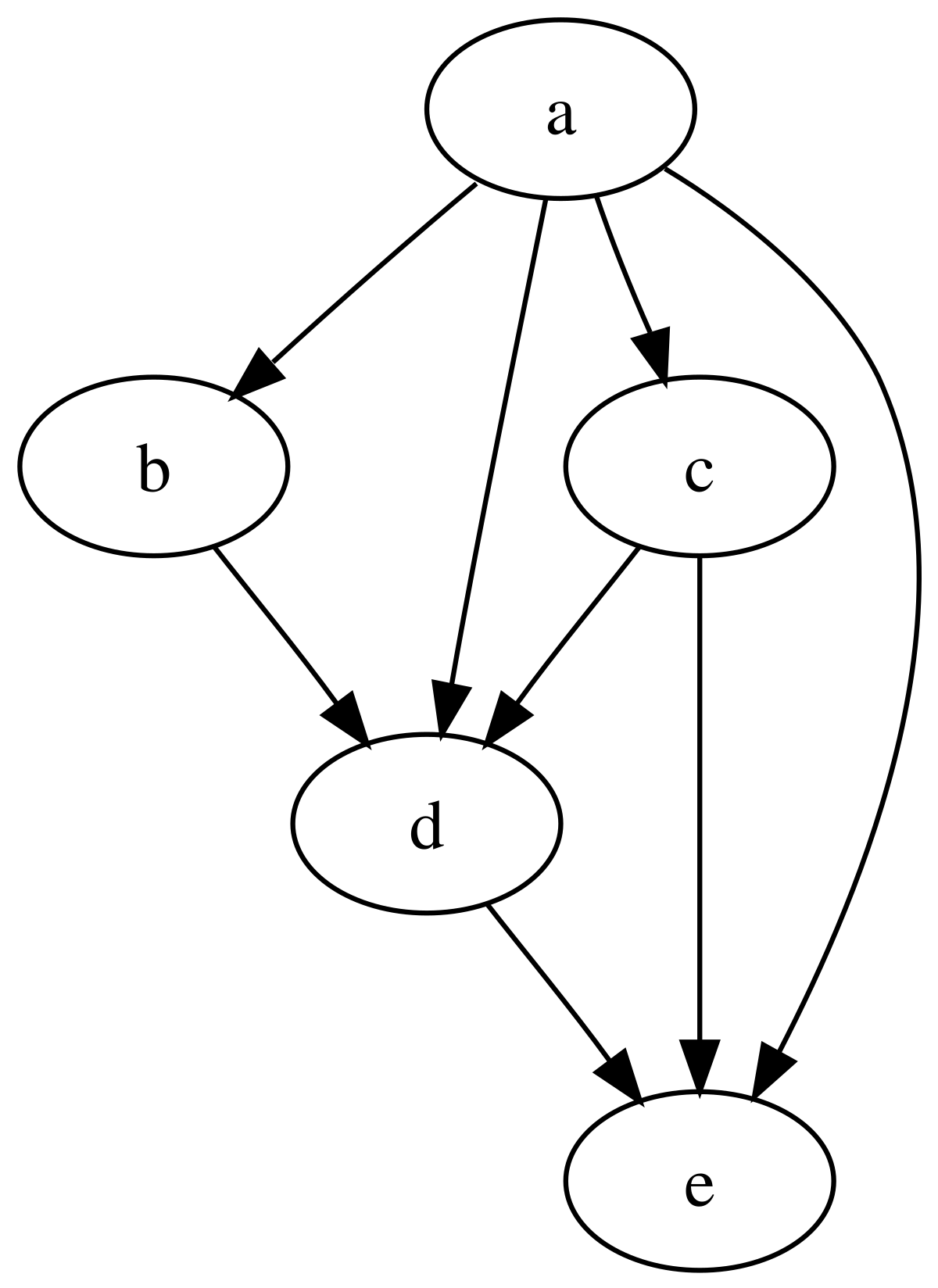
Resilient: Rdd's track data lineage information(shown below) to recover from failure state automatically. It is also known as Fault Tolerant.
Distributed: Data residing in an RDD can be stored on multiple nodes.
Lazy Evaluation: Data does not get loaded into memory until any action is called on.
Immutability: Data stored on the RDDs are in read-only mode, you can not change it.
In-Memory Computation: An RDD stores any intermediate data in RAM, so that faster access can be provided to your application.
Transformations and Actions
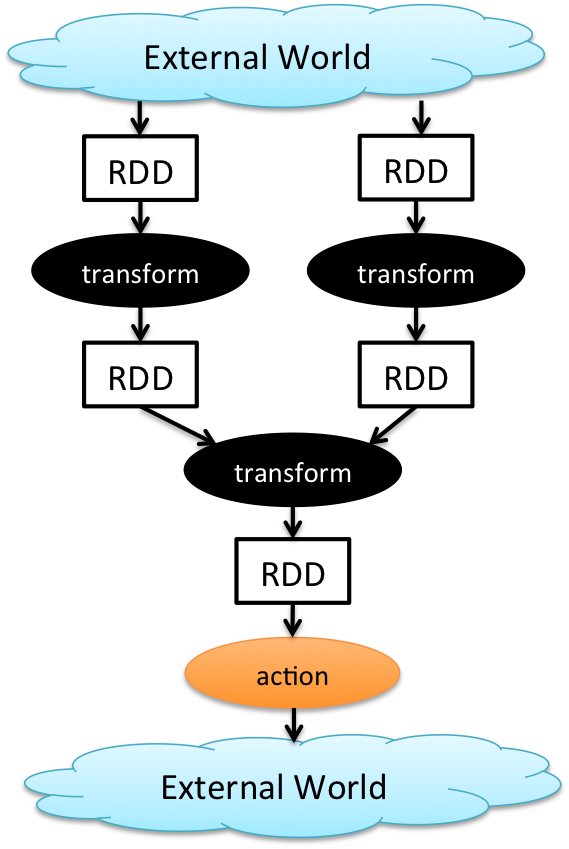
Transformations
It is a function that produces a new RDD from existing RDD, It takes RDD as input and produces RDD as output
The transformation will not be called immediately instead it will create a DAG based on reference code until the Action called
There are two types of Transformations available, Narrow and Wide Transformations
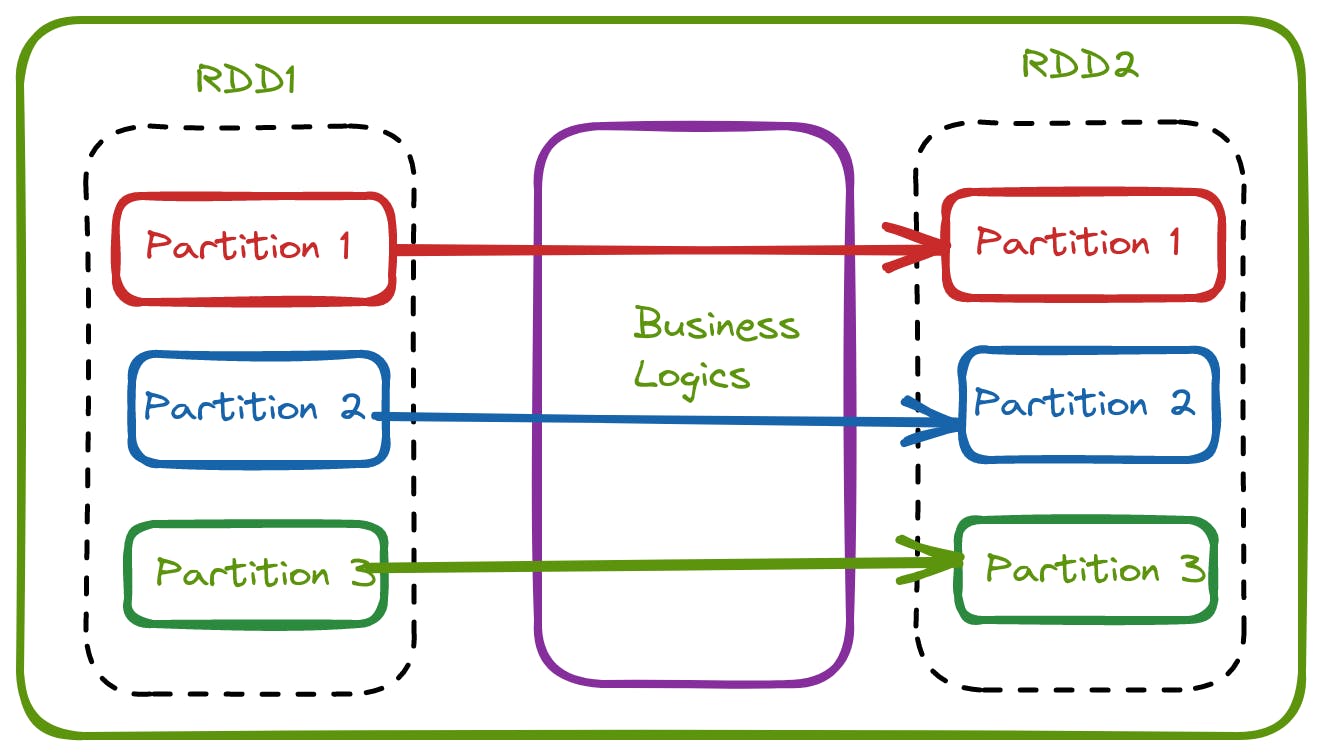
Narrow Transformations
In Narrow transformation, all the records required to compute on the single partition will be available on the single parent partition. Shuffle will not happen here.
The below-listed function uses the narrow transformations
map() filter() union()
Wide Transformation
In Wide transformation, all the records required to compute on the single partition will be available on the multiple parent partition. Due to this data shuffling will happen here.
The below-listed function uses the wide transformations
groupByKey() reducebyKey() join() repartition() coalesce()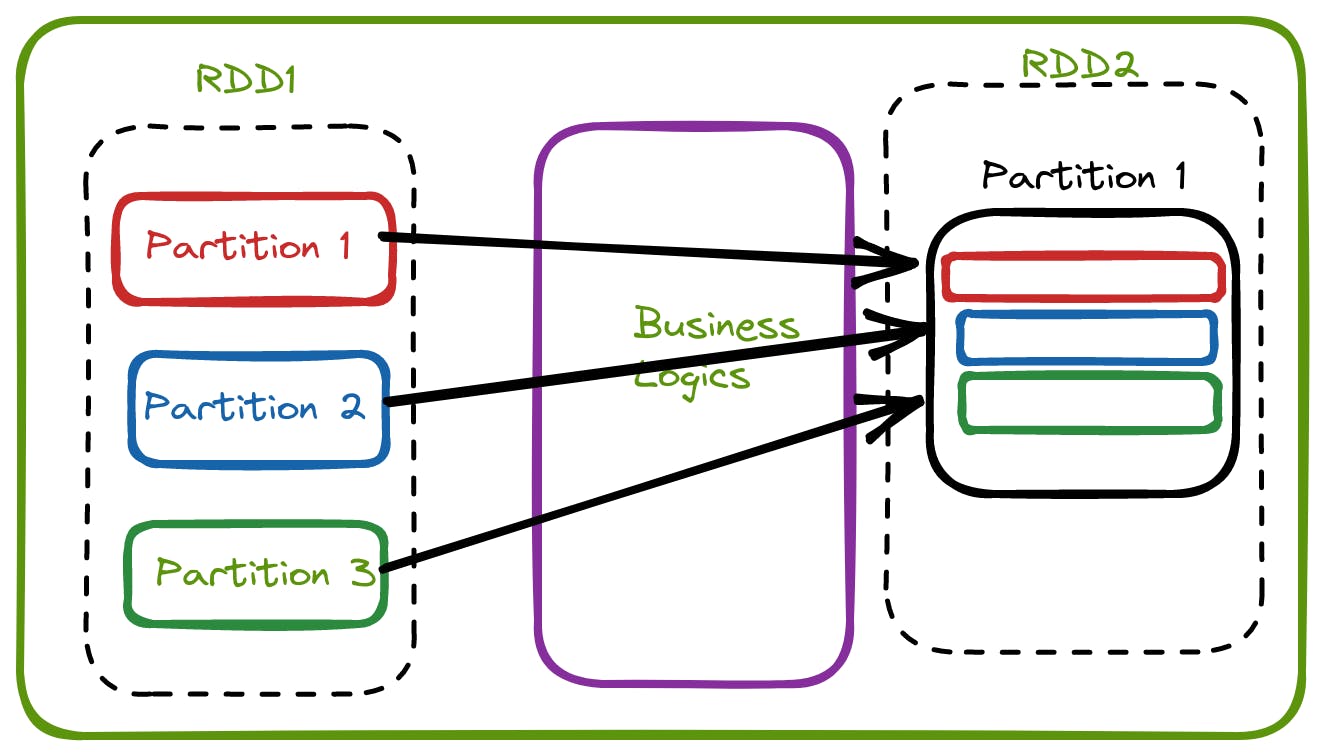
Actions
Action is the way of sending data from executors to Driver after computations from transformations.
When an action is called, a new RDD will not be created like in transformations instead it will bring actual data.
Action brings the spark of laziness into motion and this result will be stored in memory or external storage.
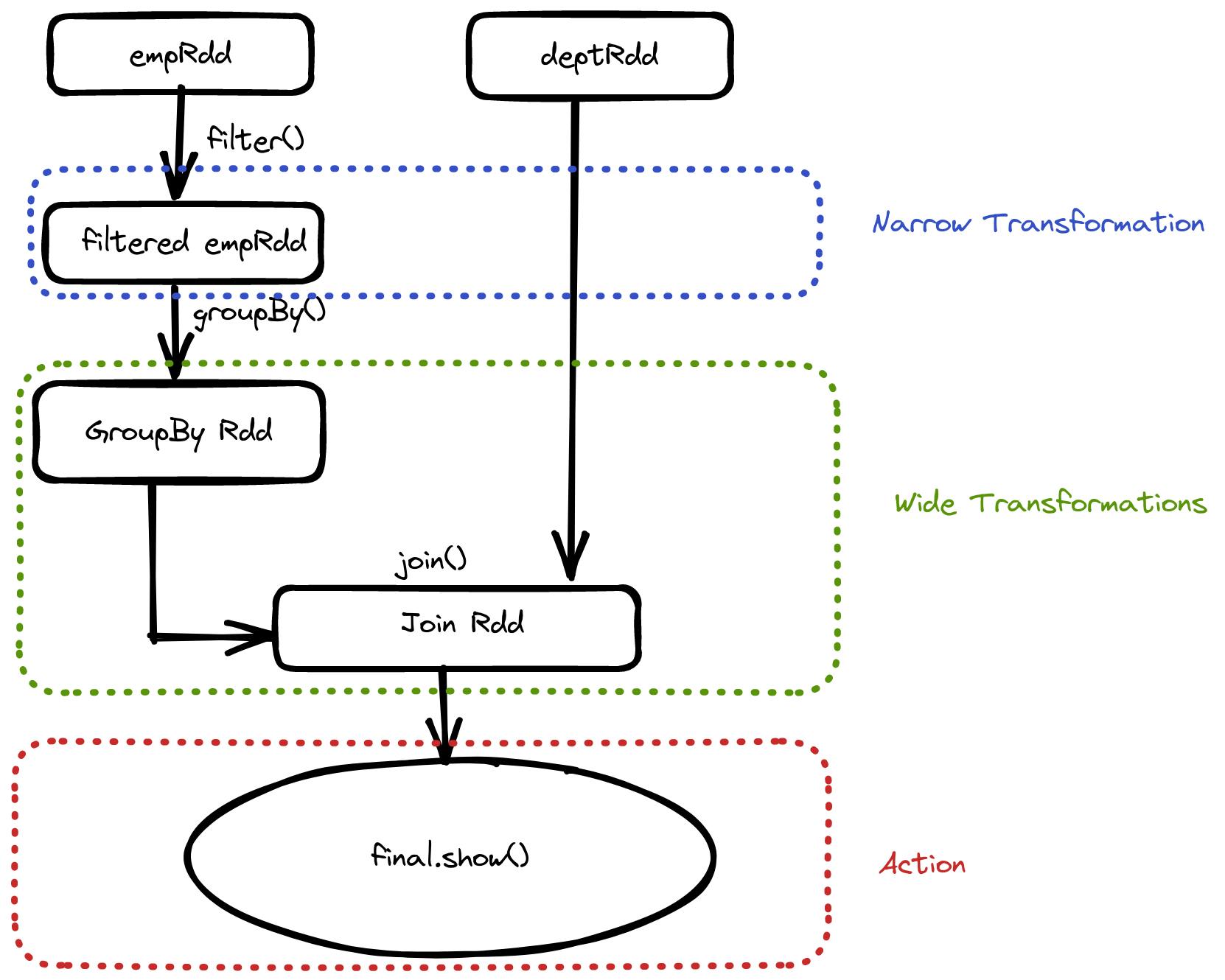
Demo PySpark application
spark = SparkSession().getOrCreate()
empRdd = spark.read_csv('emp.csv')
deptRdd = spark.read_csv('dept.csv')
filterEmpRdd = empRdd.filter("country = 'India'")
indiaDeptSalaryRdd = filterEmpRdd.groupBy('dept_id').agg(sum(), col(salary))
deptLevelSalary = indiaDeptSalaryRdd.join(deptRdd, 'dept_id', 'inner_join')
deptLevelSalary.show()