


Here we are going to learn Spark Memory Management
Before starting we need to understand the below points clearly,
One core will process one partition of data at a time
Spark partition is equivalent to HDFS blocks and repartition is possible
One task can be defined as the processing of one partition of data
To understand clearly, One core = One task = One Partition
Let's start memory management with some examples,
Consider we have a node with 32GB RAM, and we are setting the -- executor memory 4GB (Java heap memory), So that we will get 8 executors (32/4) as per our initial understanding. This number will be calculated clearly at end of this class as this is our ultimate aim of learning.
Container - Executor
As we learned earlier, An executor has a CPU, Memory unit and Network bandwidth. Like a virtual container for computation tasks.
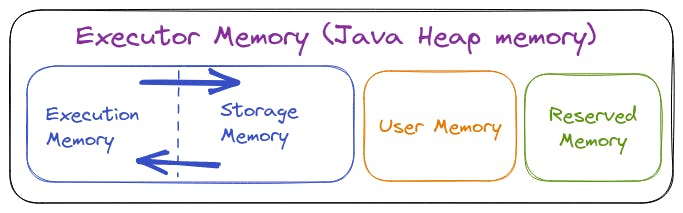
An Executor memory is a Java heap memory only which will have the below separations in it.
Two parameters control overall
Spark memory management spark.
memory.fraction = 0.75
spark.memory.storagefraction = 0.5
These two are in default value and this can configurable when needed.
Reserved Memory
Storage for running the executors, It will store the data of internal processing which will be required to execute the container.
After Spark 1.6, the Reserved Memory was fixed as 300 MB.
User Memory
It is used to store the Data structures and run user-defined functions. It can be calculated by the below formula.
(Java Heap Memory - Reserved Memory) * (1 -
spark.memory.fraction)As per our example, we will get,
\=(4GB - 300MB) * (1-0.75)
\=949 MB
Storage Memory
It is used to store the cache data, data of RDD and broadcast variables. It will follow the below formula to get the space.
(Java Heap Memory - Reserved Memory) \ (
spark.memory.fraction*spark.memory.storagefraction)*
\= (4GB - 300MB) (0.75 *0.5)
\=1423.5 MB
Execution Memory
Storage for the data required for task execution, shuffling, joining and aggregation kinds of tasks.
(Java Heap Memory - Reserved Memory) (
spark.memory.fraction* (1 -spark.memory.storagefraction)
\= (4GB - 300MB) (0.75 *(1-0.5))
\=1423.5 MB
Finally, we will have 300MB of Reserved Memory, 949 MB of User Memory, 1424 MB of Storage Memory and 1424 MB of Execution Memory. Storage and Execution memory will have their memory space whenever needed as per the below rules.
Rules for Sharing memory between Storage and Execution Memory
Storage Memory can borrow memory only when the execution memory blocks are not in use and vice versa.
If Memory blocks from execution memory are used in storage memory can evict the excess blocks occupied by storage memory.
If Memory blocks from storage memory used in execution memory can't be evicted the excess blocks occupied by execution memory. It will end up having less storage memory and will wait until the execution of some process got complete to free up memory blocks from execution memory.
Resource allocation for Spark Application
we can explicitly allocate the memory by setting below parameters in runtimes,
-- num-executors
-- executor-memory
-- executor-cores
Best practices - We can set one Executor should have 5 CPU core. Not more than this nor lesser than this.
Note - 1CPU core and 1GB of RAM can be used in each node for Operating System.
Example 1:
Lets consider we have 6 Nodes, each node have 16 cores and 64 GB RAM. after deduction we would get 15 CPU core and 63 GB of RAM on each node.
How many executors?
15CPU/5CPU = 3 Executors on each node - > we have 6 nodes - > 6*3 = 18
At max, we can have 18 virtual containers on this cluster and 1 can be allocated to Application master and another 17 can be used as Executors.
Memory for Each executors?
1 node = 3 executors and 63GB of RAM
1 executor = 63GB/3 = 21 GB , But we can't use this 21 GB as executors memory why because always we need 10% executor memory as ovehead memory is needed that also be deducted from 21 GB. To calculate overhead memory we use beow formula,
max(384 MB, 0.07*executor memory)
Finally we would use approximately 19.5 GB of RAM on executors.