Kafka Cluster
I am a data engineer who is responsible for designing, building, maintaining, and testing the infrastructure and systems that are used to store, process, and analyze data. I work closely with data scientists and analysts to ensure that the data pipelines and systems are able to support the data needs of an organization.
I have a strong background in computer science and software engineering, and skilled in programming languages such as Python, Java, and SQL also familiar with database systems and big data technologies like Hadoop, Spark, and NoSQL databases.
Some of my key responsibilities as a data engineer:
Designing and building data pipelines to extract, transform, and load data from various sources Setting up and maintaining data storage and processing systems, including data warehouses and data lakes Collaborating with data scientists and analysts to understand their data needs and ensure that the data infrastructure can support their requirements Performing data quality checks and troubleshooting any issues that arise Implementing security and privacy measures to protect sensitive data
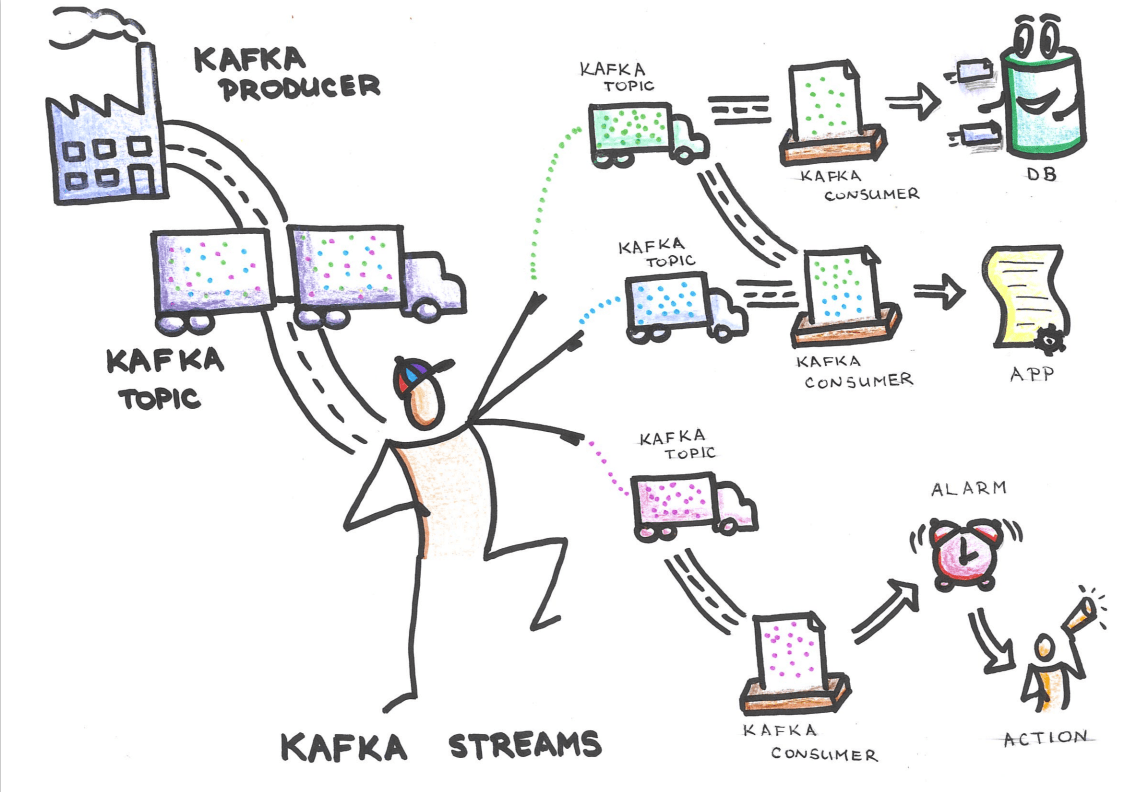
In Apache Kafka, a cluster is a group of one or more Kafka brokers working together to serve a set of topics and provide a distributed messaging service. The Kafka cluster is responsible for storing and replicating data across multiple brokers, allowing for fault tolerance and high availability.
A Kafka cluster can contain multiple brokers, each running on a separate server or node. The brokers communicate with each other using the ZooKeeper coordination service to manage partitions, assign leaders, and track the status of the cluster.
When a producer publishes a message to a topic, the message is assigned to a specific partition and replicated across multiple brokers in the cluster. This ensures that the message is stored redundantly and can be accessed even if one or more brokers fail.
Consumers can connect to any broker in the cluster and consume messages from a topic. Kafka uses a partition-based architecture to enable parallel processing of data by multiple consumers, allowing for high throughput and scalability.
Kafka clusters can also be scaled horizontally by adding or removing brokers, which allows for the processing of larger amounts of data and increases the fault tolerance of the system.
Overall, the Kafka cluster is the core of the Kafka messaging system, providing the infrastructure for storing and processing large volumes of data in a distributed, fault-tolerant manner. The ability to scale the cluster and handle large amounts of data in real-time makes Kafka a powerful tool for building data-intensive applications.
