Kafka Consumer
I am a data engineer who is responsible for designing, building, maintaining, and testing the infrastructure and systems that are used to store, process, and analyze data. I work closely with data scientists and analysts to ensure that the data pipelines and systems are able to support the data needs of an organization.
I have a strong background in computer science and software engineering, and skilled in programming languages such as Python, Java, and SQL also familiar with database systems and big data technologies like Hadoop, Spark, and NoSQL databases.
Some of my key responsibilities as a data engineer:
Designing and building data pipelines to extract, transform, and load data from various sources Setting up and maintaining data storage and processing systems, including data warehouses and data lakes Collaborating with data scientists and analysts to understand their data needs and ensure that the data infrastructure can support their requirements Performing data quality checks and troubleshooting any issues that arise Implementing security and privacy measures to protect sensitive data
In Apache Kafka, a consumer is a client application that reads messages from one or more topics in a Kafka cluster. The consumer is responsible for subscribing to a topic and receiving messages from Kafka brokers.
Consumers in Kafka can be implemented in different programming languages, such as Java, Python, or Scala, using the Kafka client API. The consumer can configure various settings, such as the consumer group, the topic subscription, and the message offset, to control the behavior of the consumer.
Kafka provides two types of consumers: a high-level consumer and a low-level consumer. The high-level consumer provides an easy-to-use API that handles many of the details of consuming messages, such as managing partitions and offsets. The low-level consumer provides a more fine-grained API that allows developers to have more control over the message consumption process.
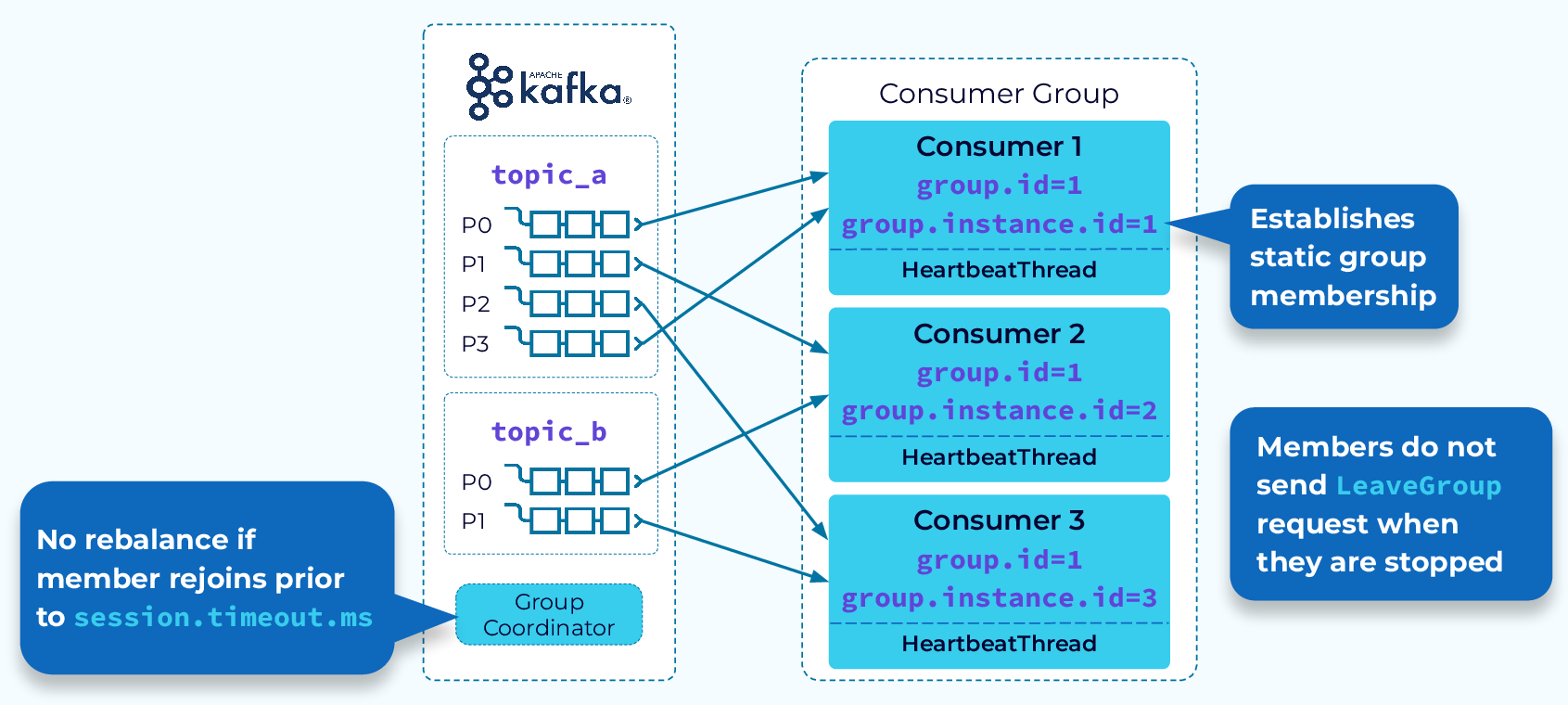
Consumers in Kafka can also be organized into consumer groups. A consumer group is a set of consumers that jointly consume a set of partitions for a topic. Each partition in a topic can be consumed by only one consumer in a consumer group. This allows for parallel processing of messages, as multiple consumers can work together to consume messages from different partitions of the same topic.
When a consumer reads messages from a partition, it keeps track of the offset of the last message it has consumed. This offset can be used to resume consumption from the point where it left off in case the consumer fails or is restarted.
Overall, consumers are a critical component of the Kafka messaging system, providing the ability to read and process data from Kafka topics in real time. By organizing consumers into groups and managing offsets, Kafka enables highly parallel and fault-tolerant processing of data across a distributed system.
