Kafka Producer

I am a data engineer who is responsible for designing, building, maintaining, and testing the infrastructure and systems that are used to store, process, and analyze data. I work closely with data scientists and analysts to ensure that the data pipelines and systems are able to support the data needs of an organization.
I have a strong background in computer science and software engineering, and skilled in programming languages such as Python, Java, and SQL also familiar with database systems and big data technologies like Hadoop, Spark, and NoSQL databases.
Some of my key responsibilities as a data engineer:
Designing and building data pipelines to extract, transform, and load data from various sources Setting up and maintaining data storage and processing systems, including data warehouses and data lakes Collaborating with data scientists and analysts to understand their data needs and ensure that the data infrastructure can support their requirements Performing data quality checks and troubleshooting any issues that arise Implementing security and privacy measures to protect sensitive data
Producer
In Apache Kafka, Producer is a client application that sends data to a Kafka cluster. The producer is responsible for publishing records on one or more Kafka topics. Each record is a Key-value pair stored in a topic partition within the cluster. The producer sends records to a Kafka broker which then writes data to appropriate Kafka topics.
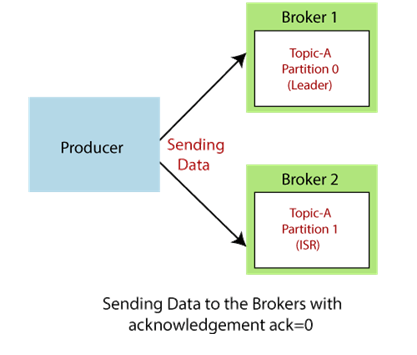
A Kafka producer can be implemented in different languages such as Python, Java or Scala, using Kafka client API. Producers can configure various settings such as compression size, partition strategy and serialization format to optimize the performance and reliability of data delivery.
The Producer can also specify the callback function that is invoked after the record is sent successfully or after an error occurs. This allows the Producer to handle different scenarios like retries or error logging.
Overall, The Producer plays a critical role in the Kafka messaging system by publishing records from different sources to Kafka topics.
